爬蟲資料不想只有 Print?用 Pandas 一秒轉成 Excel 報表
各位好! 在上一篇中我們成功用Playwright把資料撈出來並輸出在黑底白字的終端機上,但說實話,這種資料給老闆看,老闆會生氣的。這篇我們來加入 Python 資料分析的神器 Pandas,把這些雜亂的文字變成專業的 Excel 報表。 這次我們將重點放在「資料整理」的邏輯上:如何把一整串的字串,切分成乾淨的資料列。
當時我們的成果是印在終端機裡的一串文字:
2330 台積電 409610933 61.31
2317 鴻海 204784820 4.59
雖然看起來很厲害,但這種純文字資料在職場上是無法使用的。今天我們要進行爬蟲的最後一哩路:ETL (Extract, Transform, Load) 中的 Transform (轉換) 與 Load (存檔)。
目標:把那串文字,自動存成一份 0050_成分股.xlsx。
準備工具
除了 Playwright,我們需要安裝處理資料與 Excel 的套件:
pip install pandas openpyxl
Pandas: Python 資料處理的霸主,把它想像成「程式碼版的 Excel」。 Openpyxl: 讓 Pandas 能夠讀寫 Excel (.xlsx) 檔案的引擎。
程式碼解析:從文字到表格 我們原本抓到的資料 titles 其實是一個包含「換行符號 (\n)」與「空白鍵」的超長字串。
我們需要做三步驟的清洗:
Split Lines: 用換行符號把長字串切成一行一行。 Filter: 過濾掉標題(商品代碼...)和結尾(收合...),只保留真正以數字開頭的股票資料。 Split Columns: 把每一行用空白鍵切開,變成 [代碼, 名稱, 數量, 權重]。
這是整合了 Playwright 爬蟲與 Pandas 存檔的版本:
import re
import pandas as pd
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=True) # 改成 True 讓它在背景執行
context = browser.new_context()
page = context.new_page()
print("前往元大官網")
page.goto("https://www.yuantaetfs.com/product/detail/0050/ratio")
page.get_by_role("button", name="確定").click()
page.get_by_text("展開").click()
# 注意:這裡我們取 all_inner_texts 的第一個元素,這通常是整個表格的字串
raw_text = page.locator("div:nth-child(3) > .each_table").all_inner_texts()[0]
context.close()
browser.close()
print("資料抓取完成")
data_list = []
lines = raw_text.strip().split('\n')
for line in lines:
# 2. 把每一行用 "空白" 切割成欄位
# 例如: "2330 台積電 409610933 61.31" -> ['2330', '台積電', '409610933', '61.31']
parts = line.split()
# 3. 過濾邏輯:我們只要有 4 個欄位,且第一個欄位(代碼)是數字的行
# 這樣可以自動濾掉 "商品代碼" 標題列 和 "收合" 這種雜訊
if len(parts) == 4 and parts[0].isdigit():
data_list.append(parts)
columns = ["商品代碼", "商品名稱", "商品數量", "商品權重(%)"]
df = pd.DataFrame(data_list, columns=columns)
df["商品權重(%)"] = pd.to_numeric(df["商品權重(%)"])
# 預覽一下
print("\n=== 前 5 筆資料預覽 ===")
print(df.head())
# 存成 Excel
filename = "0050_成分股.xlsx"
df.to_excel(filename, index=False)
print(f"\n成功!檔案已儲存為: {filename}")
# 執行
with sync_playwright() as playwright:
run(playwright)
執行成果 當你執行這段程式碼後,終端機不再只是印出一堆字,而是告訴你檔案存好了:
前往元大官網
資料抓取完成
=== 前 5 筆資料預覽 ===
商品代碼 商品名稱 商品數量 商品權重(%)
0 2330 台積電 409610933 61.31
1 2317 鴻海 204784820 4.59
2 2454 聯發科 24688844 3.41
3 2308 台達電 32424502 3.10
4 2891 中信金 296630032 1.49
成功!檔案已儲存為: 0050_成分股.xlsx
接著打開你的資料夾,你會看到一個熱騰騰的 Excel 檔,打開來就是排版完美的表格!
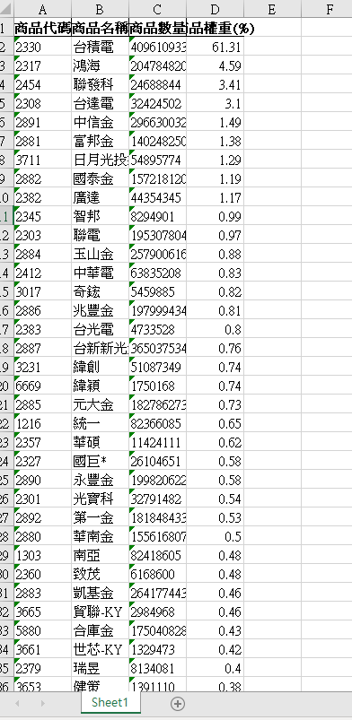
好方法推薦 isdigit() 是好朋友:在爬取表格資料時,最怕抓到「標題」或「頁尾註釋」。用 parts[0].isdigit() (判斷是否為數字) 是一個非常簡單又暴力的過濾方法,這招在抓股票代碼時特別好用。
headless=True:程式碼中我把 headless 改成了 True。這樣 Playwright 就會在背景執行,不會跳出瀏覽器視窗干擾你工作,這才是自動化該有的樣子。
學會這招,以後不管網頁上的資料多亂,只要能「看得到」,你就一定能把它變成 Excel「存起來」!
下一篇,我們挑戰更懶人的做法,把整理完的資訊通過discord bot發送給自己!
0 留言
發表留言